根据Lucene的注释,No norms means that index-time field and document boosting and field length normalization are disabled. The benefit is less memory usage as norms take up one byte of RAM per indexed field for every document in the index, during searching. Note that once you index a given field with norms enabled, disabling norms will have no effect. 没有norms意味着索引阶段禁用了文档boost和域的boost及长度标准化。好处在于节省内存,不用在搜索阶段为索引中的每篇文档的每个域都占用一个字节来保存norms信息了。但是对norms信息的禁用是必须全部域都禁用的,一旦有一个域不禁用,则其他禁用的域也会存放默认的norms值。因为为了加快norms的搜索速度,Lucene是根据文档号乘以每篇文档的norms信息所占用的大小来计算偏移量的,中间少一篇文档,偏移量将无法计算。也即norms信息要么都保存,要么都不保存。
下面几个试验可以验证norms信息的作用:
试验一:Document Boost的作用
public void testNormsDocBoost() throws Exception { File indexDir = new File("testNormsDocBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); doc1.setBoost(100); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); Document doc3 = new Document(); Field f3 = new Field("contents", "common common common", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc3.add(f3); writer.addDocument(doc3); writer.close();
public void testNormsFieldBoost() throws Exception { File indexDir = new File("testNormsFieldBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("title", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); f1.setBoost(100); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); writer.close();
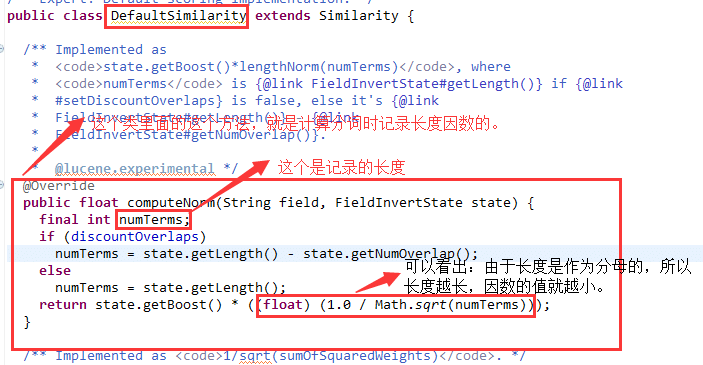
public void testNormsLength() throws Exception { File indexDir = new File("testNormsLength"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello hello hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); writer.close();
public void testOmitNorms() throws Exception { File indexDir = new File("testOmitNorms"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); Document doc1 = new Document(); Field f1 = new Field("title", "common hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); for (int i = 0; i < 10000; i++) { Document doc2 = new Document(); Field f2 = new Field("contents", "common common hello hello hello hello", Field.Store.NO, Field.Index.ANALYZED_NO_NORMS); doc2.add(f2); writer.addDocument(doc2); } writer.close(); }
public void testQueryBoost() throws Exception { File indexDir = new File("TestQueryBoost"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common1 hello hello", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common2 common2 hello", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); writer.close();
public void TestCoord() throws Exception { MySimilarity sim = new MySimilarity(); File indexDir = new File("TestCoord"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello world", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common common common", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); for(int i = 0; i < 10; i++){ Document doc3 = new Document(); Field f3 = new Field("contents", "world", Field.Store.NO, Field.Index.ANALYZED); doc3.add(f3); writer.addDocument(doc3); } writer.close();
@Override public TokenStream tokenStream(String fieldName, Reader reader) { TokenStream result = new WhitespaceTokenizer(reader); result = new BoldFilter(result); return result; }
}
class BoldFilter extends TokenFilter { public static int IS_NOT_BOLD = 0; public static int IS_BOLD = 1;
public static int bytes2int(byte[] b) { int mask = 0xff; int temp = 0; int res = 0; for (int i = 0; i < 4; i++) { res <<= 8; temp = b[i] & mask; res |= temp; } return res; }
public static byte[] int2bytes(int num) { byte[] b = new byte[4]; for (int i = 0; i < 4; i++) { b[i] = (byte) (num >>> (24 - i * 8)); } return b; }
}
然后,实现自己的Similarity,从payload中读出信息,根据信息来打分。
class PayloadSimilarity extends DefaultSimilarity {
@Override public float scorePayload(int docId, String fieldName, int start, int end, byte[] payload, int offset, int length) { int isbold = BoldFilter.bytes2int(payload); if(isbold == BoldFilter.IS_BOLD){ System.out.println("It is a bold char."); } else { System.out.println("It is not a bold char."); } return 1; } }
public void testPayloadScore() throws Exception { PayloadSimilarity sim = new PayloadSimilarity(); File indexDir = new File("TestPayloadScore"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new BoldAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED); Document doc1 = new Document(); Field f1 = new Field("contents", "common hello world", Field.Store.NO, Field.Index.ANALYZED); doc1.add(f1); writer.addDocument(doc1); Document doc2 = new Document(); Field f2 = new Field("contents", "common <b>hello</b> world", Field.Store.NO, Field.Index.ANALYZED); doc2.add(f2); writer.addDocument(doc2); writer.close();
It is not a bold char. It is a bold char. docid : 0 score : 0.2101998 docid : 1 score : 0.2101998
如果scorePayload函数如下:
class PayloadSimilarity extends DefaultSimilarity {
@Override public float scorePayload(int docId, String fieldName, int start, int end, byte[] payload, int offset, int length) { int isbold = BoldFilter.bytes2int(payload); if(isbold == BoldFilter.IS_BOLD){ System.out.println("It is a bold char."); return 10; } else { System.out.println("It is not a bold char."); return 1; } } }
则结果如下,同样是包含hello,包含加粗的文档获得较高分:
It is not a bold char. It is a bold char. docid : 1 score : 2.101998 docid : 0 score : 0.2101998