

下图是一个典型的Lucene4.x的索引结构图:
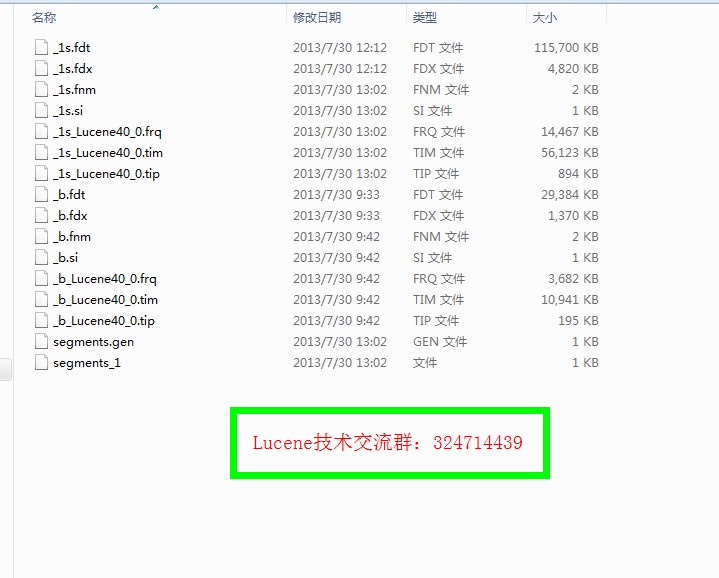
Lucene4.x之后的所有索引格式如下所示:
| 文件名 | 后缀 | 描述 |
| Segments File | segments.gen, segments_N | 存储段文件的提交点信息 |
| Lock File | write.lock | 文件锁,保证任何时刻只有一个线程可以写入索引 |
| Segment Info | .si | 存储每个段文件的元数据信息 |
| Compound File | .cfs, .cfe | 复合索引的文件,在系统上虚拟的一个文件,用于频繁的文件句柄 |
| Fields | .fnm | 存储域文件的信息 |
| Field Index | .fdx | 存储域数据的指针 |
| Field Data | .fdt | 存储所有文档的字段信息 |
| Term Dictionary | .tim | term字典,存储term信息 |
| Term Index | .tip | term字典的索引文件 |
| Frequencies | .frq | 词频文件,包含文档列表以及每一个term和其词频 |
| Positions | .prx | 位置信息,存储每个term,在索引中的准确位置 |
| Norms | .nrm.cfs, .nrm.cfe | 存储文档和域的编码长度以及加权因子 |
| Per-Document Values | .dv.cfs, .dv.cfe | 编码除外的额外的打分因素, |
| Term Vector Index | .tvx | term向量索引,存储term在文档中的偏移距离 |
| Term Vector Documents | .tvd | 包含每个文档向量的信息 |
| Term Vector Fields | .tvf | 存储filed级别的向量信息 |
| Deleted Documents | .del | 存储索引删除文件的信息 |
复合索引文件是指,除了段信息文件,锁文件,以及删除的文件外,其他的一系列索引文件压缩一个后缀名为cfs的文件,意思,就是所有的索引文件会被存储成一个单例的Directory,而非复合索引是灵活的,可以单独的访问某几个索引文件,而复合索引文件则不可以,因为其压缩成了一个文件,所以在某些场景下能够获取更高的效率,比如说,查询频繁,而不经常更新的需求,就很适合这种索引格式。
lucene索引的基本概念组成由,索引,文档,域和项组成,一个索引,通常包含一些序列的文档,一个文档包含一些序列的域,而一些域又包含一些序列的项,而一些项则包含一些列序列的最低层的字节,注意这里的序列指的是在索引结构中有序,通常有序的这种方式,某些情况可以优化索引结构。
lucene使用了倒排索引(Inverted Indexing),来存储索引信息,大大提高了检索效率,
倒排索引,举一个通俗的例子,原来基于人们的正常思维,我们会存储的是一个文章中出现了那几个单词,而倒排索引,却恰恰相反,它存储的是这个单词,包含在几个文档中,当然这个关系是由倒排链表(存储一系列docid)构成的索引,我们在检索时,通过这个单词可以快速的定位,它出现在几篇文章中,从而大大提升了检索性能。
当然lucene中不仅仅有倒排索引,也有正向的存储,而倒排之所以是lucene的核心,是因为它提升了检索性能,在检索到一个个具体的文档时,就需要我们正向的拿出这些信息,反映在实际的代码中就是我们通过检索获取一个个docid,然后通过一个个docid获取整个文档,然后我们在正向的获取各个域,以及各个项存储的具体信息,当然前提是你存储了这个字段,如果你只是索引了,而并没有存储,那么你只能检索到此条信息,但无法获取具体term的值,这个需要在建索引之前就要设计好,索引的存储结构,那些字段是检索的,那些字段是存储的等等,如果你还需要高亮一些内容,则还需要存储这个域的偏移的位置,通过这样就能准确的在文中标记检索命中的关键词,如果你打算在前台来完成这个高亮,就不要存储这些信息了。